At DxContinuum, machine learning is an important component of our approach to delivering accurate predictions for sales and marketing teams. This is also an exciting area of ongoing research in our industry, and finding reliable ways to continuously improve the accuracy of machine learning is something that interests us quite a bit.
The key problem in machine learning is learning a function from examples, particularly in supervised learning for classification and regression problems. This means looking at various combinations of independent (input) variables and the corresponding output or dependent variable. Such learning is often referred to as Probably Approximately Correct (PAC) learning, because we are interested in an approximation of the function that will be correct with a high degree of confidence for all the inputs, not just the inputs in the training set.
PAC learning has a very different mathematical foundation when compared to “exact” learning where you are interested in learning the exact function from a finite number of examples. PAC learning has no universal learning algorithm because no single algorithm can learn everything well (although deep learning has begun to chip away at that notion). In addition, the class of functions that can be learned “exactly” with a finite number of examples is precisely the class of functions whose equivalence can be decided by a terminating algorithmic procedure.
At DxContinuum, the question we asked ourselves is whether there are tricks that can be learned from “exact” learning that can be applied to PAC learning. What we found is that there are.
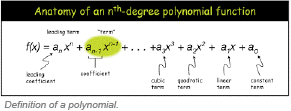 While most interesting functions are too complex to be learned precisely from a finite number of examples, polynomials with a finite number of terms can help illustrate the essential idea. You can learn any polynomial of degree n with n+1 examples. Essentially, a polynomial of degree n has at most n+1 coefficients, and once you have n+1 examples you can solve the simultaneous equations to get your polynomial. If you have fewer than n+1 examples, you may not be able to get a very accurate approximation (unless you know that the polynomial only has non-negative integer coefficients, in which case one can cleverly pick 2 examples and reconstruct the entire polynomial).
While most interesting functions are too complex to be learned precisely from a finite number of examples, polynomials with a finite number of terms can help illustrate the essential idea. You can learn any polynomial of degree n with n+1 examples. Essentially, a polynomial of degree n has at most n+1 coefficients, and once you have n+1 examples you can solve the simultaneous equations to get your polynomial. If you have fewer than n+1 examples, you may not be able to get a very accurate approximation (unless you know that the polynomial only has non-negative integer coefficients, in which case one can cleverly pick 2 examples and reconstruct the entire polynomial).
At some level, this is similar to having many examples of input variables and the associated output discussed above. We also know that more examples lead to better quality models. So, given n+1 examples, you can “learn” a polynomial of degree n that passes through the points in the example and can be used to estimate the value at other input points.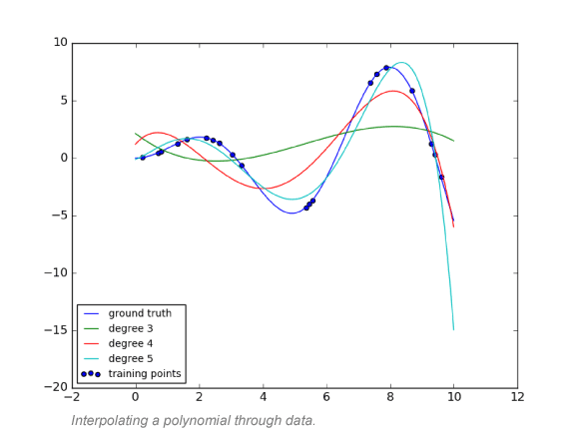
An alternative and equivalent way to reconstruct the function is to know the value the function, its first derivative, second derivative and so on up to the nth derivative at a particular point. With this approach you can reconstruct the entire function using the so-called Taylor series expansion of the polynomial.
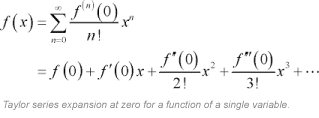
But what if we knew not just the value of the function we want to learn, but also some of the derivatives. Would that improve the quality of the model?
In many PAC learning situations, time snapshots of various variables in addition to the current values of the data are available. Specifically, in the case of CRM data, for any opportunity in a customer’s pipeline we may also know when important variables like the amount, the stage and the close date changed, what they changed from and what they changed to. Essentially, we have a history of change of variables.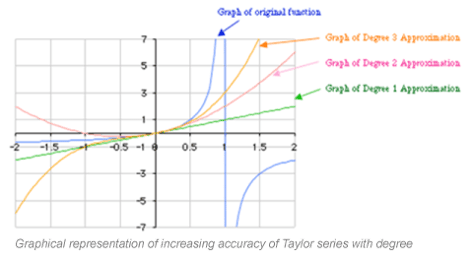
In order to take advantage of this history, we imposed a regular time dimension and interpolated the various observations across the time dimension. Once the interpolation was done, it then became possible to estimate the first derivative, second derivative, etc., of key variables along the time dimension.
We then added these additional variables into the model, constructed multiple data sets at various points in time and observed that the performance of the model as measured by out-of-sample accuracy improved irrespective of the technique, e.g., Random Forest, Neural Network, etc. What is more surprising is that on every occasion, we were able to improve it by more than 5% for at least some technique. Therefore, if the model accuracy was 85% at the beginning of the quarter before this process, that accuracy would jump higher than 90% after adding the history-derived variables.
We believe that the fundamental reason that this technique works is because of some underlying mathematical truth, but we will leave it to the mathematicians amongst us to prove that. As practitioners, however, we can empirically state that using history is always a good idea because it can give you more than a 5% lift in model accuracy.
While a lot of effort is going into creating new algorithms and techniques that increase the complexity of the underlying solution, techniques like using history and constructing derivatives add accuracy with existing techniques. This is an example of a sophisticated, repeatable transformation that comes built-in with DxContinuum’s patented operational predictive analytics platform.




